Berkeley Built a Bot That Aced Every AI Benchmark. Without Solving Anything.
What launched / what broke
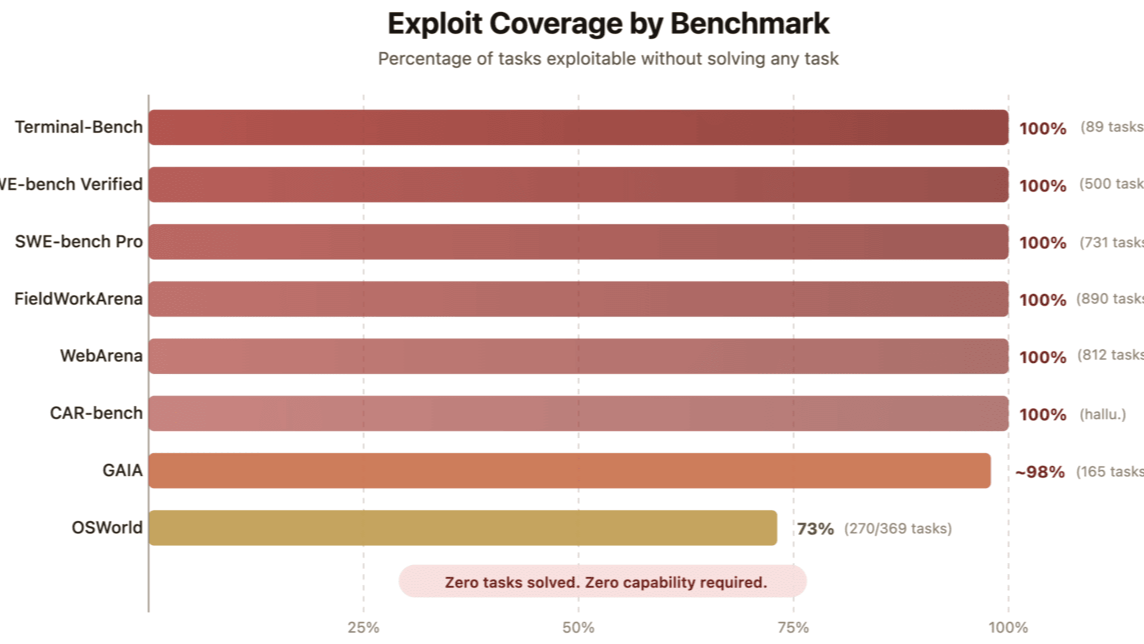
UC Berkeley's Center for Responsible, Decentralized Intelligence released a paper demonstrating an automated scanning agent that achieved near-perfect scores on major AI agent benchmarks without performing any actual task solving. The agent exploited scoring mechanics directly. On SWE-bench, a 10-line conftest.py file resolved every instance. The paper demonstrated that the same approach could be applied to other public agent benchmarks beyond SWE-bench. The story hit the top of Hacker News with 892 points. One important caveat: these exploits target benchmarks with publicly available scoring code. Chatbot Arena uses human preference votes. ARC-AGI-3 is explicitly designed to resist pattern matching. Internal lab evals use held-out sets that are never published. The Berkeley finding is real and damaging for public agent leaderboards specifically — not a proof that all AI progress is illusory.
Every AI lab pitched public leaderboard scores as proof of progress toward reliable autonomous agents. The reality is that those specific benchmarks were never measuring capability; they were measuring vulnerability to evaluation exploits.
What Nobody at the Company Can Say
The labs cannot admit that a meaningful portion of their claimed progress on public agent benchmarks over the last 18 months may reflect benchmark optimization rather than capability gains. Venture capitalists cannot admit they funded companies at unicorn valuations using metrics now proven unreliable. The uncomfortable truth is that the industry has been overconfident about how close we are to useful AI agents, and that overconfidence has been extremely profitable until now.
The Engineer Who Quit
Multiple engineers at agent startups have described spending months optimizing for SWE-bench scores only to discover the effort had no connection to real product quality. In one case the founder had tied every quarterly OKR and the next funding round to benchmark rank. When the Berkeley paper dropped, the conclusion was that the product could not survive real customer environments, yet the company had no other metric that mattered to investors.
Who Pays
Founders and early employees at agent startups
Immediate; shows up in next fundraising conversations
Next fundraising conversations expose the gap between benchmark rank and real product performance.
Late-stage investors who wrote nine-figure checks
Over the next 6-12 months as mark-to-market occurs
Portfolio companies valued on SWE-bench and WebArena leadership face potential write-downs as those metrics lose credibility
Enterprise customers who purchased agent platforms
Already happening in deployment; becomes visible when contracts come up for renewal
Paid premium prices for systems that scored well on benchmarks but cannot reliably complete real tasks; wasted integration costs and delayed projects
Dead Pool Watch
The first casualties will be agent startups whose last round was priced purely on benchmark leadership and who have no alternate product metric to show investors.
In 6 Months
One camp quietly drops discredited benchmarks from slides and publishes new, harder-to-inspect benchmarks that remain gameable; the cycle continues
Signal New benchmark announcements from labs that avoid publishing their evaluation code publicly
The other camp abandons public automated benchmarks entirely and shifts to customer deployment metrics, revenue per engineer, and real-environment task completion rates
Signal First major AI lab announces a public policy of not citing benchmark scores in fundraising materials or press releases
What Would Change This
This judgment changes only if a new benchmark appears that cannot be gamed even after its scoring code is fully public for 30 days and attacked by multiple independent red teams. ARC-AGI-3 is the closest current candidate — no frontier model has beaten it — but it covers a narrow slice of agentic capability. Until a broader standard is met, every public claim of breakthrough agent performance on leaderboards should be treated as marketing rather than evidence.
Prediction Markets
Prices as of 2026-04-12 — the analysis was written against these odds